
Alvaro Cassineli & Can Liu, 2020
VivaVoce invites its public to discuss around a table. As soon as a word escapes a mouth, it begins a life of its own over the table, desperate to join some others as close as possible in meaning. It swim around for a while, exploring a confusing semantic ocean. If it is lucky, it joins a pack and swirls in synchrony, a school of fish that slowly enlarges as it accepts newcomers. With time, the table is filled with keywords aligning with the arguments put forward; but the flock can disolve anytime as the conversation goes if a new “semantic kindom” emerge. Indeed, the rules are hard in this ocean of words: if a word finds no close allies (either because it is off topic or worse, if it contradicts an emerging semantic status quo), it will shrink and eventually die alone on the shore – along with all the unlucky particles and pronouns. On the contrary, if it reinforces the topic, it is allowed to live longer, thriving and growing in its group. When the speakers are silent or no one is around, all the words will eventually die except for one big fish that in a sense summarizes the topic of the conversation that just took place in the world of humans.

The survival of the “fittest opinion“ on social networks
VivaVoce is a visual metaphor of how memes and “truth” form in our digitally mediated world, in particular online social networks. Once uttered, one cannot expect words to dissolve in thin air as it was the case in the past – instead, words (and by extension opinions) live and thrive in the digital medium. Invisible processes involving algorithms (as well as humans) force upon them a process of natural selection leading to the emergence of memes, unreasonable consensus, reinforced biases and polarized opinions. Everybody wants to have the last word, but the truth is that we are not in control. Perhaps we never were in control. As David Bohm put it in “Thoughts as a System” (1994):
“Thought runs you. Thought, however, gives the false information that you are running it, that you are the one who controls thought, whereas actually thought is the one which controls each one of us.”
However, the problem is infinitely more complex today. Controlling this this evolution (including arbitrary processed of runaway selection) is practically impossible in online platforms, even for the tech giants supporting its infrastructure. Strategies based on AI filters will always backfire – in fact these are just additional sources of evolutionary pressure that in a more or less obvious way reflect its creators’ biases.
In truth, policing the Word of Words is downright impossible. There is only one obvious (but difficult solution) to this problem: better think twice before opening one’s mouth…
Technical details

Our system is composed of four parts:
- Voice detection and real time speech-to-text, using vosk Python package and a pretrained model (KaldiRecognizer). This runs as a process in the main computer (a mac laptop);
- Natural language processing (NLP) algorithms to produce a word embeding, this is, representing each word as a real-valued vector in a 300-dimensional space. We use the package Genisim and word2vec, trained in a large corpus of text (in English, but it would be easy to make the system multilingual). Both the word (as ASCII text) and it’s vector representation (a list of 300 numbers) is sent to a Processing sketch (below);
- Sound source localization is done independently using dedicated hardware. Data from a circular microphone array feeds a powerful microcontroller (Reaspeaker Mic Array V.2) running a Python script that extracts the direction of arrival (DOA) using generalized cross-correlation algorithm. The final estimate (0 to 360 degrees), is subsequently sent to the main computer through a serial interface;
- Finally, a Processing sketch that gathers all this information generates the dynamic visuals. The sketch runs a server and receives data from the word embedding python script through a local TCP/IP. This sketch perform semantic analysis and simulate the selective forces and visuals:
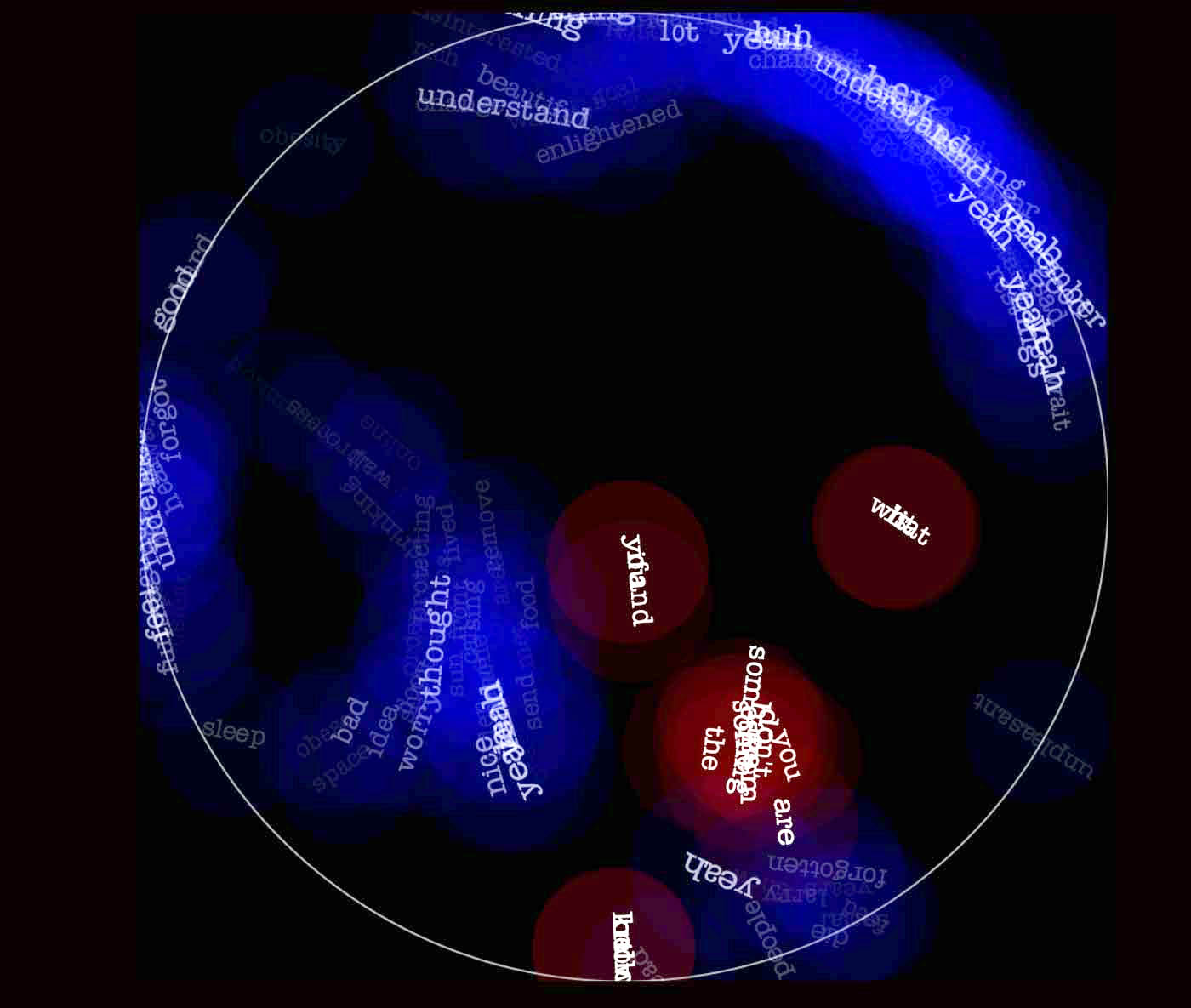
- First, it computes the average vector from all the words “on the table”. This vector does not necessarily represents a word, but the semantic center of gravity of all the word’s meaning – that is, a point in a 300 dimensional space that somehow represents the “topic” of the conversation.
- Then, it computes for each word over the table it’s semantic distance to this “center of gravity” using an appropiate measure, the cosine distance. Semantic distances between all the words are also computed (in a pair-wise manner) to generate flocking forces (see below);
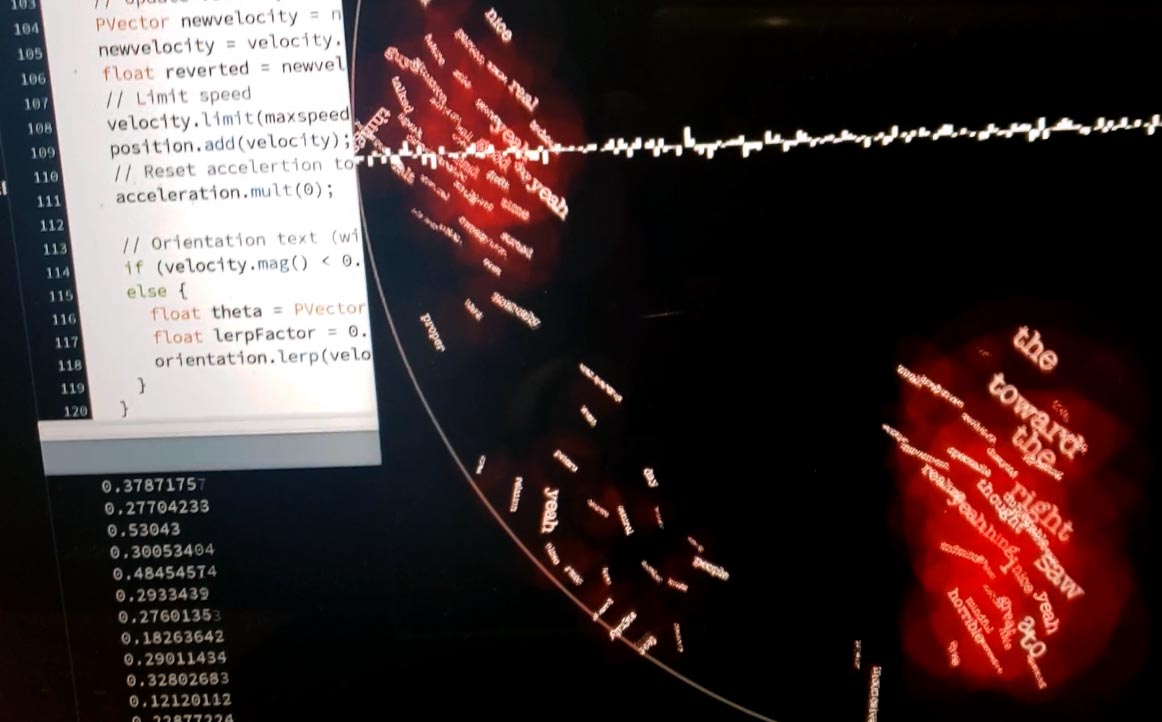
- Finally, this Processing sketch generate the visuals. We modified the classic boid algorithm (swimming behaviour) by adding attractive and repulsive forces between words, weighted by the inverse of their semantic distance. In parallel, the size of each words as well as their life time is a function of their distance to the current semantic center of gravity.
Emergent Behaviours



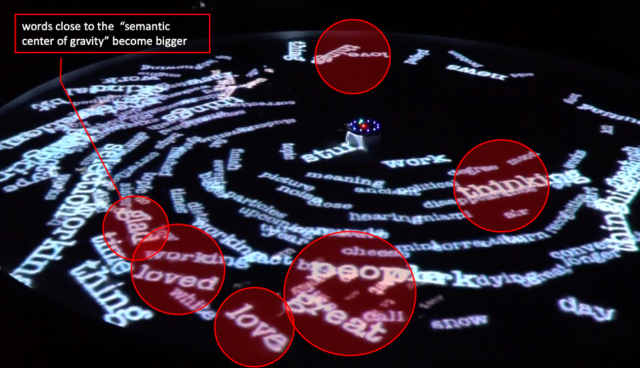
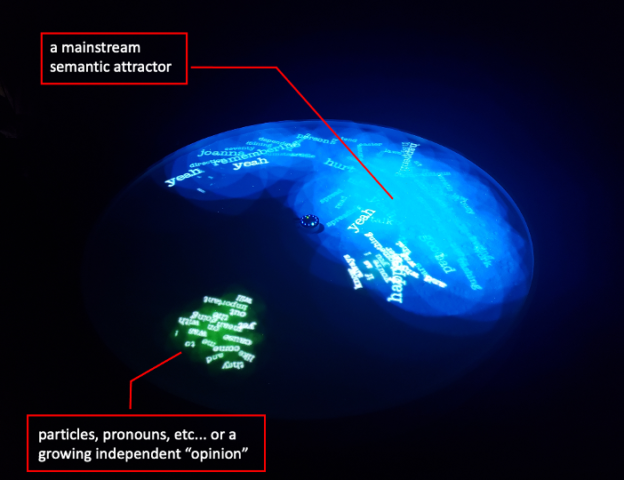
During testing, I used Homer’s Illiad to feed the installation. It didn’t take long for the table to distill the epic poetry from the first few hexamers. Jorge Luis Borges short story “The Aleph” was also interesting, as metaphysics related terms slowly filled the space:

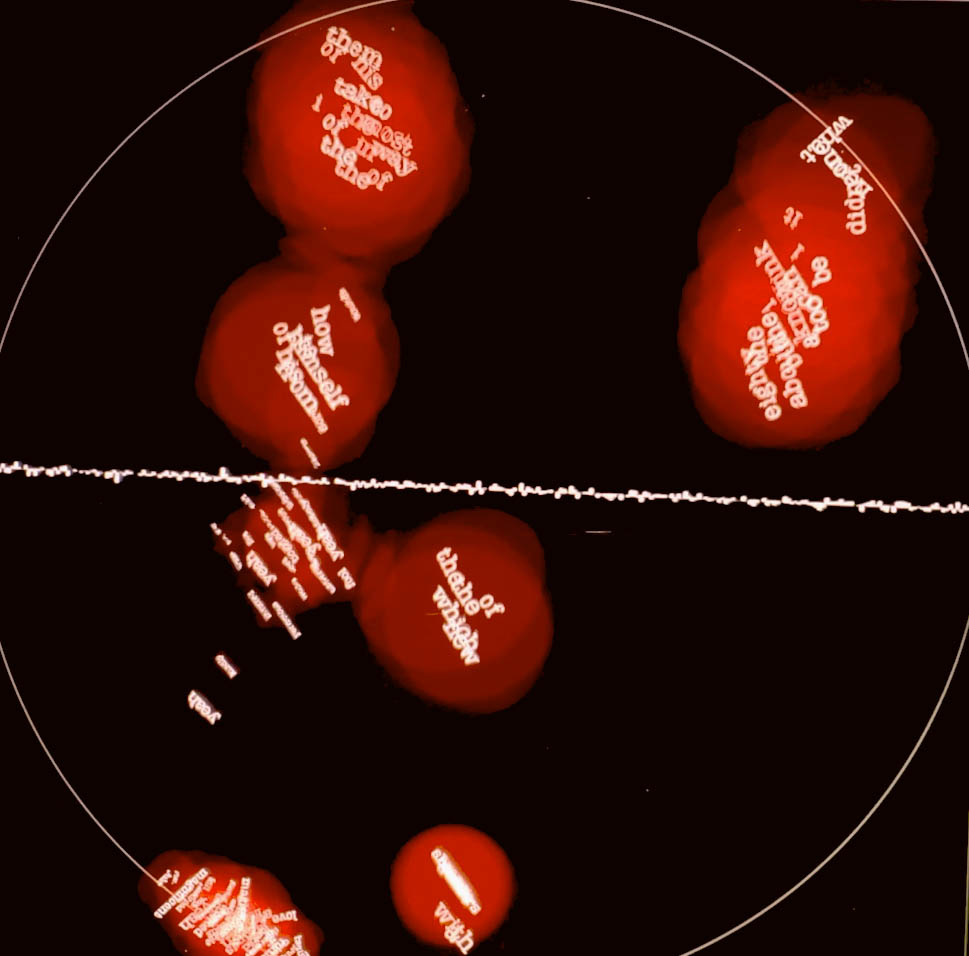





Exhibition history
- VivaVoce (in collaboration with Can Liu). Comissioned for Art Machines Past & Present exhibition, Curated by Richard Allen and Jeffrey Shaw, Indra and Harry Banga Gallery, CityU Hong Kong, Nov.24 2020 -Feb.21 2021.